Abstract
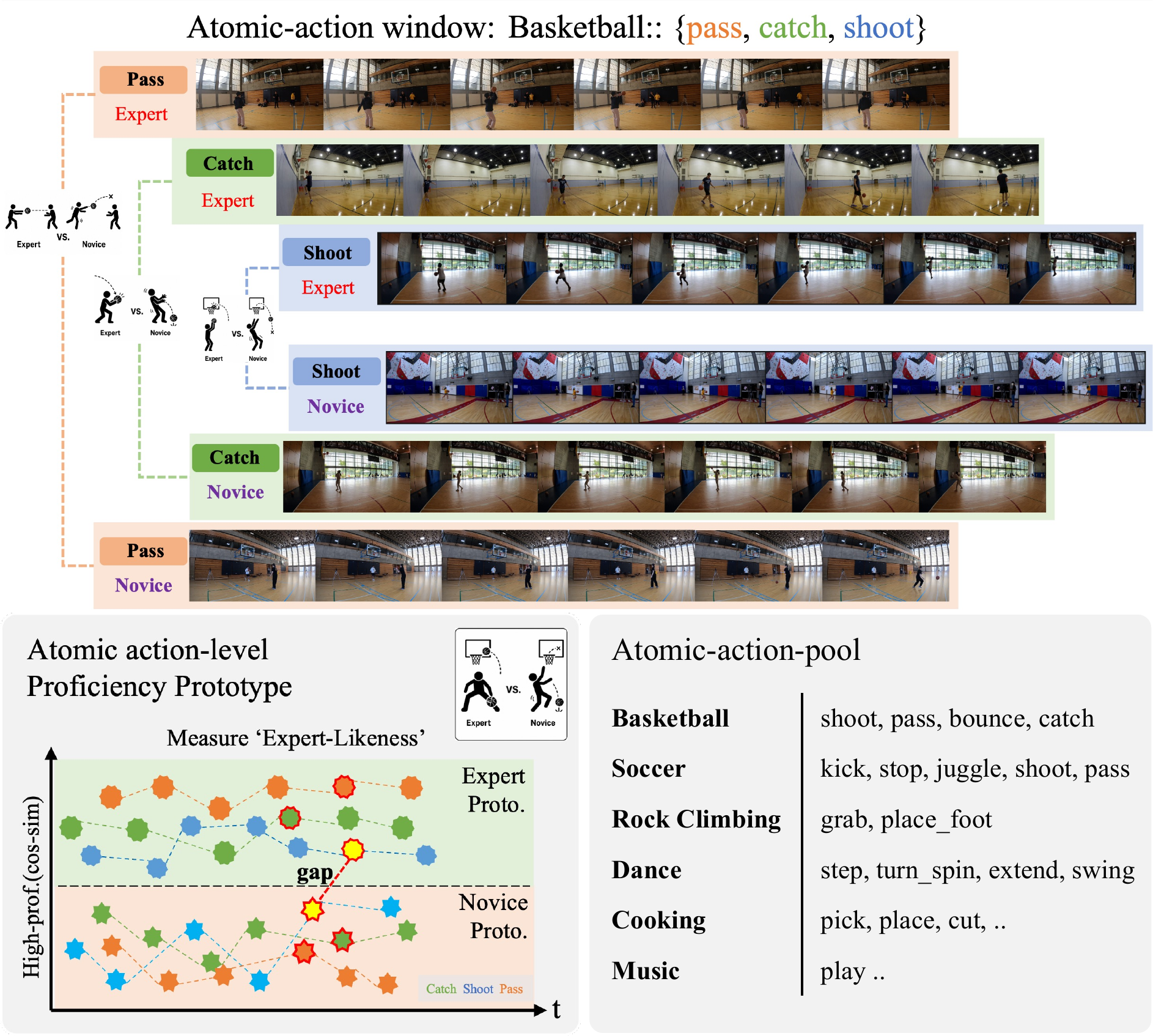
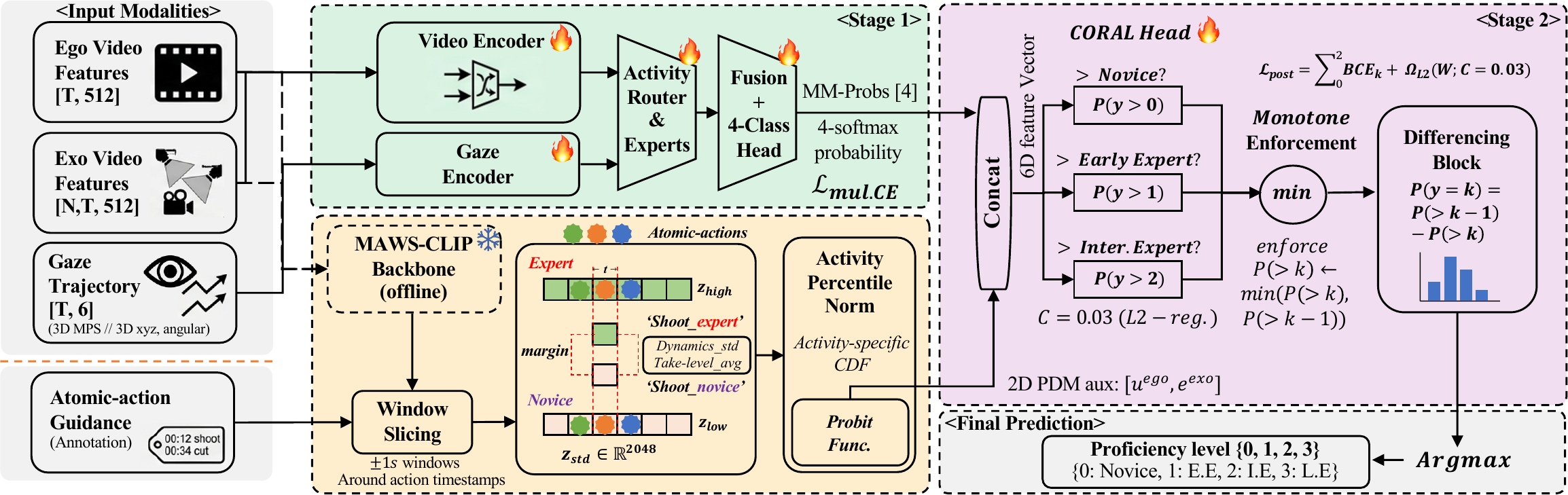
Human proficiency estimation is challenging because skill is a high-level and often subjective property that is not captured by action identity alone. Existing approaches leverage multimodal observations such as ego-exo video, gaze, pose, and inertial signals, but the gap between sensor-level evidence and abstract proficiency labels remains difficult to bridge. We address this gap by using language annotations as temporal guidance rather than direct semantic supervision. Specifically, atomic action descriptions decompose each activity into proficiency-relevant action windows, where we extract dense visual dynamics from frame-level features. We then summarize each action window into an action-dynamics feature and compare it against high- and low-proficiency prototypes constructed from expert and novice executions within the same activity-action category, yielding a high-low prototype margin that measures relative execution quality.